Natural Language Processing
Natural Language Processing is everything to do with getting computers to understand human language. It’s a branch of AI but is really a mixture of disciplines such as linguistics, computer science, and engineering.
Why would I need Natural Language Processing?
Has your boss ever asked you to make a summary in Excel of how much all your customers spend? If the data is in an Excel already, then the task is easy.
But what if your company processes fixes to new-build houses? Every homeowner sends in a form with the problems (electrical fault, damp, damaged plasterboard) described in plain text. Your boss asks you to find the commonest construction faults. These are all in PDF files submitted by homeowners. How could you do this in Excel? Where would you even start?
You might be tempted to read through a sample of the documents and summarise them qualitatively for your boss. Of course, this is not a bad idea, and will give you insights. But we can do more…
Natural Language Processing
Unfortunately we don’t yet have a tool as simple as Excel for analysing unstructured text data. But there is a whole field of study dedicated to this kind of problem: Natural language processing (NLP).
Computers are very good at calculating faster than we can - for example, averaging numbers to find the mean customer spend. But they are not so good at unstructured data, although they are getting better.
If I was tasked with synthesising faults from homeowner documents like in my above example, I would proceed as follows:
- get hold of the data in PDF or Word format and convert it all to plain text
- read through the text manually and identify any common patterns
- understand how this set of documents is a problem for the business and what result from an NLP exercise could save them money
- depending on the business analysis, potentially run the text data through an algorithm such as LDA, which could identify clusters (topics) in the document.
- if necessary, hand-label some examples and train a classifier which can categorise a new incoming document into electrical, damp, structural, scratch, etc (whichever categories we decide on)
- the business may want a deployed classifier which can triage incoming documents, or assign them to high or low risk, cost, complexity, or identify other information in the documents which help business processes.

Why is NLP important?
Natural language processing helps us convert unstructured data sources, such as an unorganised set of documents, into structured values that a computer can process. Human language is very complex and hard to model. For example, linguists have debated for years which category human languages fall into in the Chomsky Hierarchy of Languages.
When I first started in the field in 2007 (studying a Masters), there was a lot of focus in NLP on developing sets of rules to model a language such as English. This is incredibly difficult and NLP systems would often break down when they encountered unfamiliar inputs (such as a strange sentence structure, slang, spelling and grammar mistakes, or unseen languages and vocabulary).
Now, the field has moved towards more data-driven approaches, where tech giants such as Google can train large language models (LLMs) on terabytes of data, without needing a linguist to laboriously hand-code a language’s grammar into a programming language. But the problem remains, that unstructured data is difficult to handle. Organisations with large amounts of documents are often sitting on an untapped goldmine because they do not have the expertise in-house to extract value from their text data. In any industry with large amounts of documents, such as legal, pharma, insurance, construction, regulation, R&D, or humanities research, a company which can leverage its in-house text data will naturally get a head start on its competitors.
How is NLP used in business?
Here are a few examples of common business applications of natural language processing.
| Business function | Application of NLP |
|---|---|
| Customer service | Chatbots on company websites. These reduce call centre costs and allow companies to run analytics on chat logs. |
| Customer service | Triaging incoming emails using a classifier |
| Operations | Estimate the risk of a clinical trial protocol failing, or the cost of a repair. |
| Operations | Machine translation: Google, Azure translate |
| Market research | Machine learning models such as Whisper can transcribe interviews with Key Opinion Leaders (KOLs) in pharma |
| Operations | Document summarisation models |
| Operations | Identify key products or locations mentioned in a text, and extract their relationships. For example, a doctor says “I would prescribe (DRUG) with (DRUG)”, and a smart model may be able to identify the relationships between the entities. |
How does NLP work?
There are two main approaches to NLP: symbolic NLP and statistical NLP, although a hybrid is becoming more popular.
- Symbolic NLP was the dominant approach from the 1950s to the 1990s, and involved programmers coding grammar rules and ontologies into a system, cataloguing real-world and linguistic knowledge.
- Statistical NLP is currently the dominant approach, where machine learning algorithms such as neural networks are trained on vast corpora of data, and learn common patterns without being taught the grammar of a language.
What are the challenges of NLP?
Human language is very complex and hard to codify. Even the rules in a grammar book are regularly broken, to the point that it is not possible to hand-code a parser to read and interpret a sentence. If you attempt to hand-code a system to categorise building defect reports into groups, or extract structured data from them (let’s say, to identify which room contains the scratched drywall), you will quickly hit a point of diminishing returns, where new documents contain wording or phrase structures that haven’t been considered before. There are thousands of languages in the world, each with their own complex grammars. Words can be ambiguous, humans use slang, sarcasm, make spelling mistakes, or use metaphors and nuances, all of which can flummox a machine. The best we can hope for at the moment is to develop a statistically-trained model for a particular, very narrow, purpose - whether that’s triaging construction reports for risk, identifying sentiment around drugs, or identifying key persons mentioned in a text.
What are the stages of NLP?
Traditionally, many NLP libraries, such as spaCy or the Stanford Parser, follow a series of steps to mould a sentence into something a computer can handle.
Let’s take the input text, “I love languages.” This would typically go through a series of components to eventually output a parse tree.
| Stage | Output |
|---|---|
| Tokeniser | “I”, “love”, “languages”, “.” |
| Part of speech tagger | PRON, VERB, NOUN, PUNCT |
| (Stemmer) | “i”, “love”, “language”, “.” |
| Lemmatiser | “I”, “love”, “language”, “.” |
| Parser | 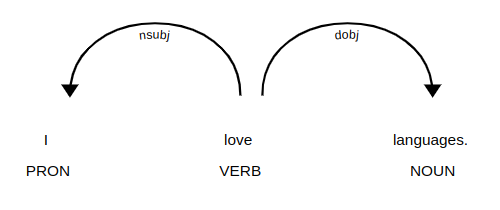 |
However, in recent years the more statistical approach has taken hold, where an incoming document is tokenised and converted into a series of vectors using an algorithm such as Word2vec or a Transformer. The data can then be input into numerical models such as a classifier (what kind of fault is this?) or a risk model (what is the risk of this error report escalating?).
How can I learn NLP?
There are some excellent books and videos which I would recommend:
Speech and Language Processing by Jurafsky and Martin

Speech and Language Processing was my core textbook when I studied my Masters in NLP in 2008 and is still top of the list. Speech and Language Processing is a general overview of traditional and modern approaches in the field, encompassing the two subfields of text and speech which are sometimes dealt with separately. Daniel Jurafsky and James H. Martin have kept their book up-to-date with new developments in the field, such as word vector representations. The book has a strong applied focus that allows users to apply their skills in real-world situations, and the authors have put the third edition draft online.
Foundations of Statistical Natural Language Processing by Manning and Schütze
This book is also available online and presents a thorough introduction to statistical approaches to natural language processing.
Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit by Bird et al
If your language of choice is Python, this book will help you get off the ground quickly using a valuable Swiss army knife, the Natural Language Toolkit (NLTK).
Deep Learning by Goodfellow, Bengio et al
The Deep Learning Textbook is a great comprehensive guide to everything related to machine learning and neural networks. It will help you understand the theory, whereas the NLTK book above is about practice.
Video series: Hugo Larochelle
Hugo Larochelle from the Université de Montréal has put an excellent series of video lectures online.
Resources for planning a Natural Language Processing project
NLP is unfortunately less straightforward than some fields such as software engineering. It is often hard to ascertain at the outset, whether a project will be feasible, and what kind of results can be extracted.
When you’re beginning a data science or NLP initiative in an organisation, I would recommend that you identify a number of candidate projects and quantify the technical effort required and the business impact of each one. This will help you to prioritise. You can try using this data science roadmap template, which provides a handy table to fill out.
I find it’s also informative to identify the risks associated with a project. Some risk factors are general to project management, and others are unique to NLP. I have put together a list of high-risk and medium-risk indicators here.
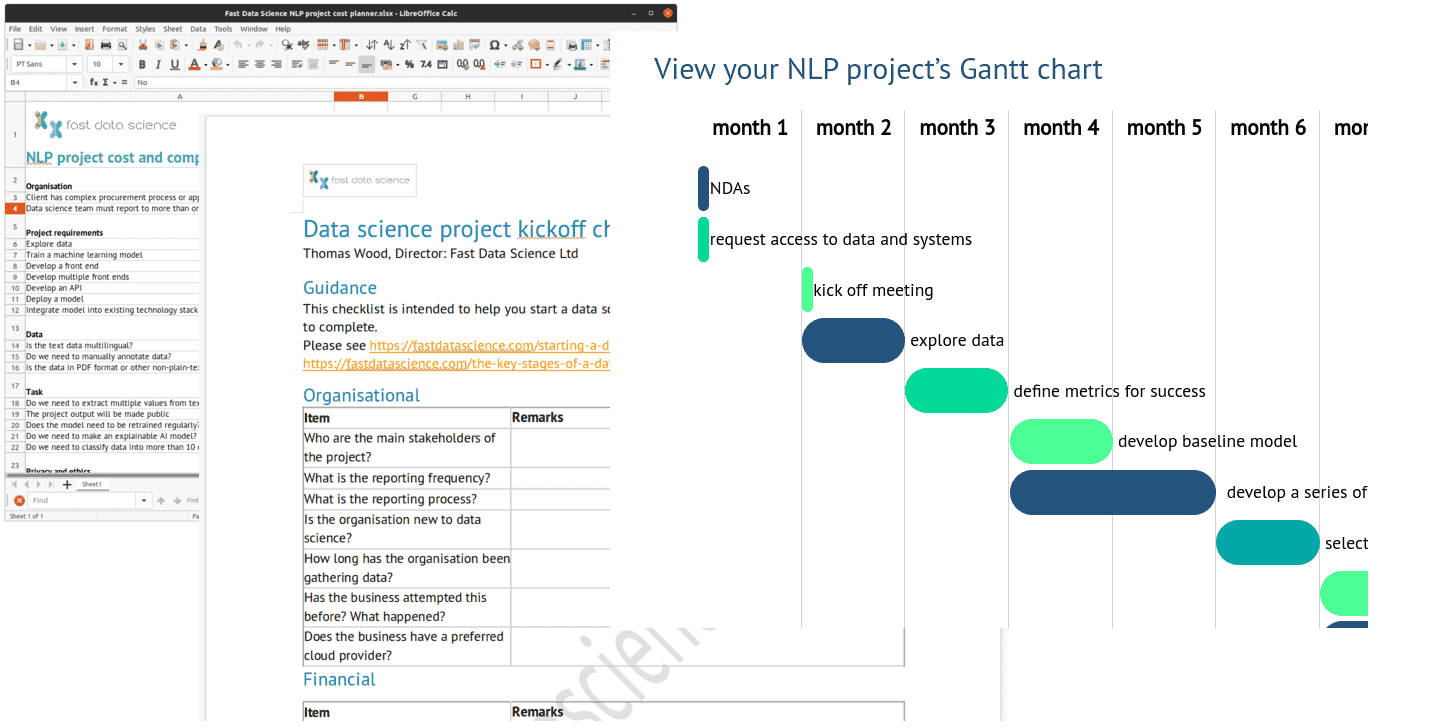
Finally, although data science projects don’t always lend themselves to traditional project management patterns, it’s still an informative exercise to put together a rough Gantt chart for your project. You can try this interactive NLP project planner which allows you to choose the parameters of your project, and will generate a Gantt chart for you.
There are a number of other handy resources for NLP project planning and management on the Resources section of our website.
Getting started with Natural Language Processing
If you have a large number of unstructured documents and you are struggling to extract value from them, please get in touch with us at fastdatascience.com.
About the author
 |
Thomas Wood is the director of Fast Data Science Ltd. He has more than 12 years’ experience in natural language processing and machine learning. He has consulted for large organisations such as Tesco and the NHS, and recently has specialised in NLP for the pharmaceutical industry. |